API Rate-Limiting

.png)
APIs are the medium through which different systems communicate, including social networking, all the way to typical corporate applications. Which means that they are very powerful, but without appropriate regulation, they are prone to overuse or misuse.
This is where API rate limiting comes in. Without a strong rate-limiting system, APIs can get saturated, and this leads to slow response time, system crashes, or even system downtimes. But what does API rate limiting mean? Rate limiting decides the number of requests that a user can make to an API call within a specific period.
API rate limiting examples are all around, across a wide range of businesses and sectors, thanks to the growing popularity of APIs. Applications like X or GitHub, where a user can make a large number of API requests. Rate limiting makes sure no single user floods their services while at the same time allowing high demand. Similarly, it’s used to control the number of logins, since it is important to protect against brute force attacks.
There are several different types of rate-limiting strategies. For example:
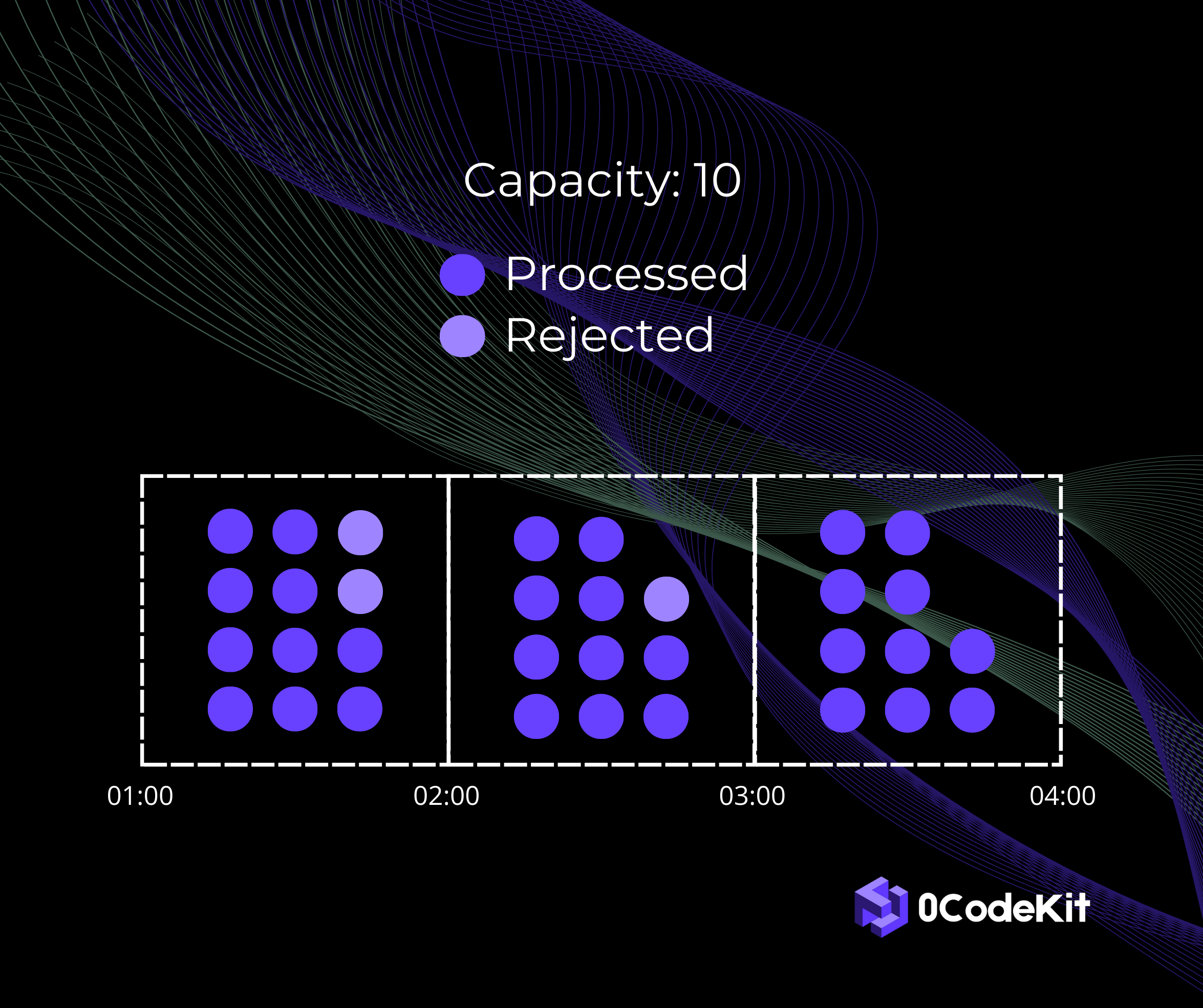
It is one of the simplest, but most effective means of regulating the flow of traffic to your API. It operates based on the client’s number of requests in each period, also called "window".
Suppose you have a rule that allows 100 requests per minute. Every minute, a new window opens, and in that time frame, all the requests get counted. So long as the user does not exceed the allowed number of requests, everything will be fine. However, if the requests surpass this limit in a certain time interval, all the following requests are either denied or moved to the next time slot.
The sliding window is a much more effective and accurate mechanism of regulating API traffic than the fixed window. This approach makes the traffic smoother and more consistent by using a “sliding” time window that is constantly changing.
The sliding window, in contrast, does not reset the request counter whenever a new fixed window begins. The sliding window calculates the rate limit over a rolling period. This means that the system will look back some X seconds or minutes to check whether the request limit has been reached.
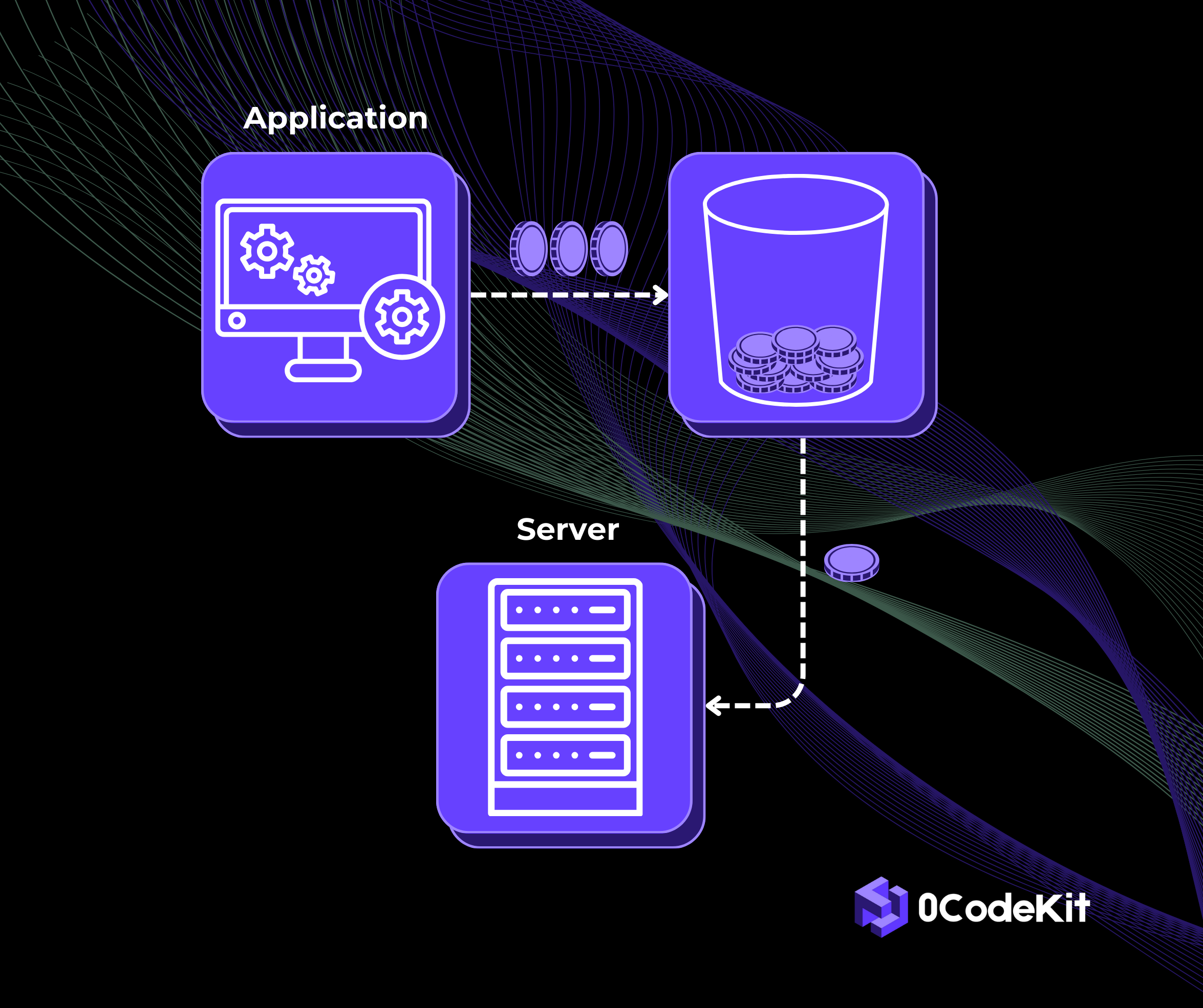
The leaking bucket effectively helps in managing API requests by regulating the traffic for a particular period. Let's say you have a bucket with one little hole at the bottom. As in the case of water (or in this case, requests), they can only flow out at a steady rate, no matter how fast new requests flood in.
It is a bucket where an API request, when arriving, is completed to the fullest. If the bucket is full, the request either must wait or be dropped. However, over time, the requests trickle down at a steady pace. This helps to keep the process requests smooth and avoid waves that might overwhelm the system and slow down processing.
Visualise a bucket that is gradually filling up with tokens over time. One token equals permission to make an API call. When a request comes in, it takes a token from the bucket. If there is a token in the bucket, the request is processed. If the bucket is empty, the request must sit back until there are more tokens before it can be processed again.
Tokens are gathered in the bucket at a constant pace, so that you can handle a consistent traffic flow. But here’s where the token bucket stands out: this approach also allows flexibility. If your bucket has collected additional tokens, then you can handle a large traffic influx – up to the size of the bucket – without a problem. When the bucket is empty, the traffic slows down to match the rate of the new tokens coming.